More than 400,000 new games

Hundreds of thousands of new games played in 2020 were added to the new Mega Database 2021. A lot of these games were played by renowned grandmasters and are annotated by well-known ChessBase authors.
Navigating the database is easier than ever: the Mega Database menu makes it easy to prepare for your games, to search for tournaments, to find annotated games or to access all the games in the database.
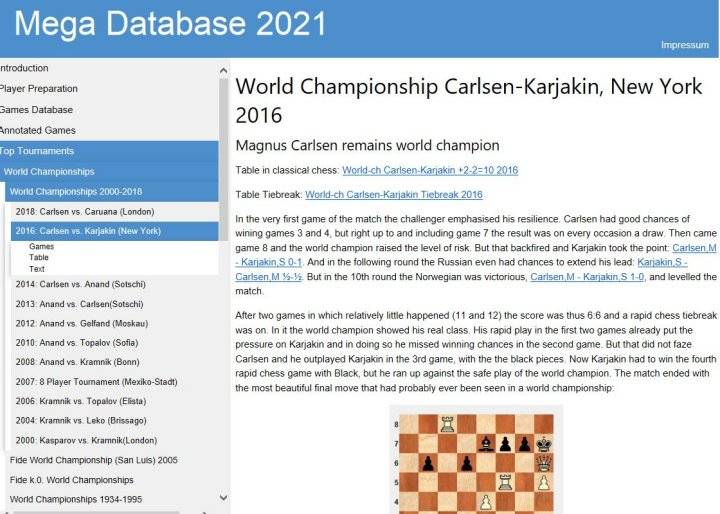
One improvement: all World Championship matches, Women’s, Juniors and Senior’s World Championships tournaments were added and a lot of top tournaments can be directly accessed via the menu — with tables, all games, and texts about the tournaments which give you additional information and insights.
Tournament information, e.g. Tournament text to the World Chess Championship 2016, or to recent top tournaments as Wijk aan Zee 2020, Biel Masters 2020 or Gibraltar Masters 2020. All games from the World Champion matches, a lot of them with annotations and analysis by top grandmasters offer insights to all the games.
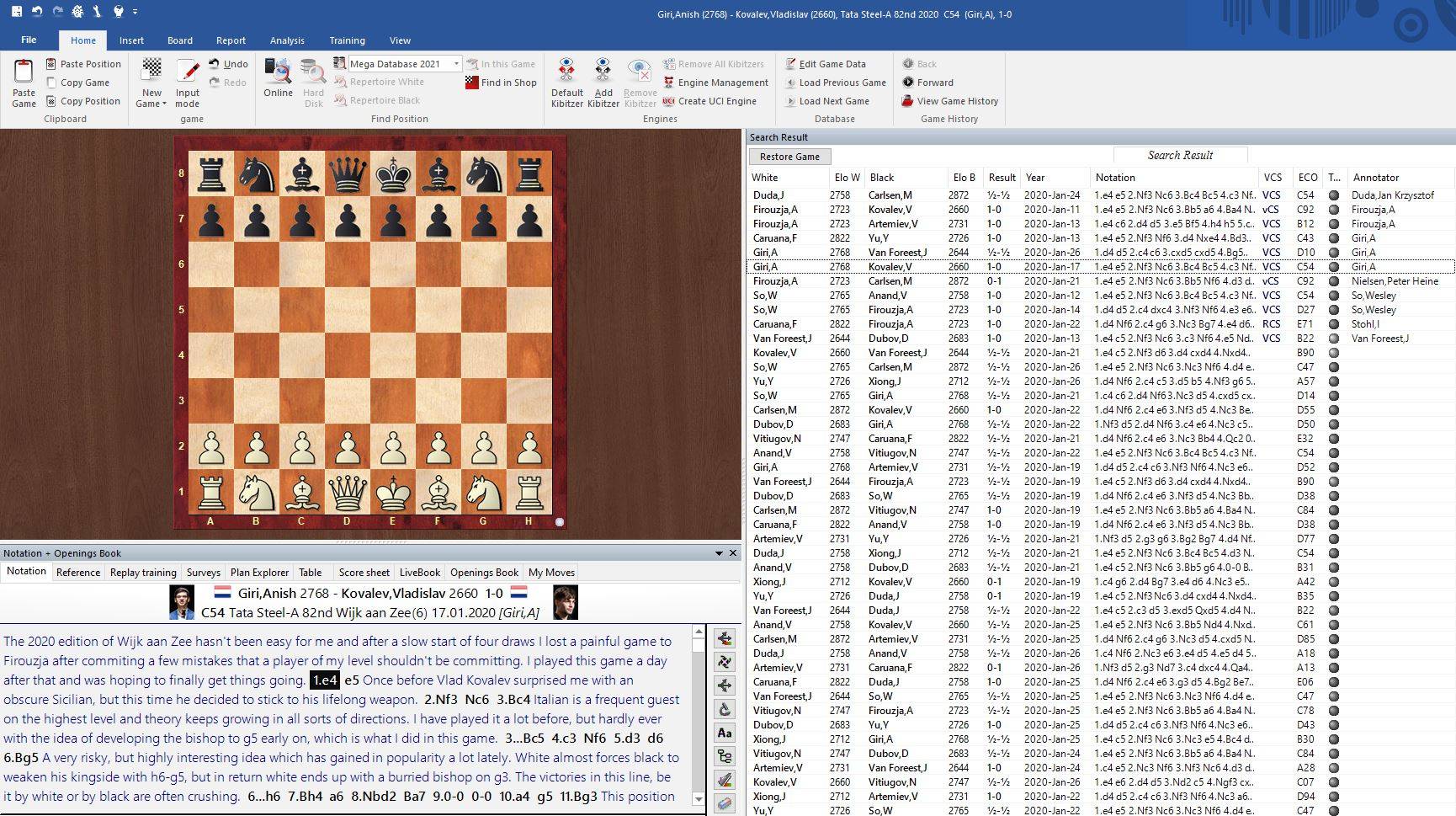
The ChessBase Mega Database 2021 is the premiere chess database with over 8,4 million games from 1560 to 2020 in high quality. Packing more than 85,000 annotated games, Mega 2021 contains the world‘s largest collection of high-class analysed games. Train like a pro! Prepare for your opponents with ChessBase and the Mega Database. Let grandmasters explain how to best handle your favorite variations, improve your repertoire and much more.
Preparing for your next opponent is easy: with the Mega Database it just takes seconds to find the games of your next opponent! The repertoire overview shows you which lines your opponent likes to play and statistics reveal weaknesses in his repertoire. The reference search allows you to find critical opening positions easily: put the position on the board and click the reference-button. You can filter games/ e.g. your research, to look for annotated games to deepen your understanding.
Prepare for your next opponent or find your own games, just enter his name to get to the games:
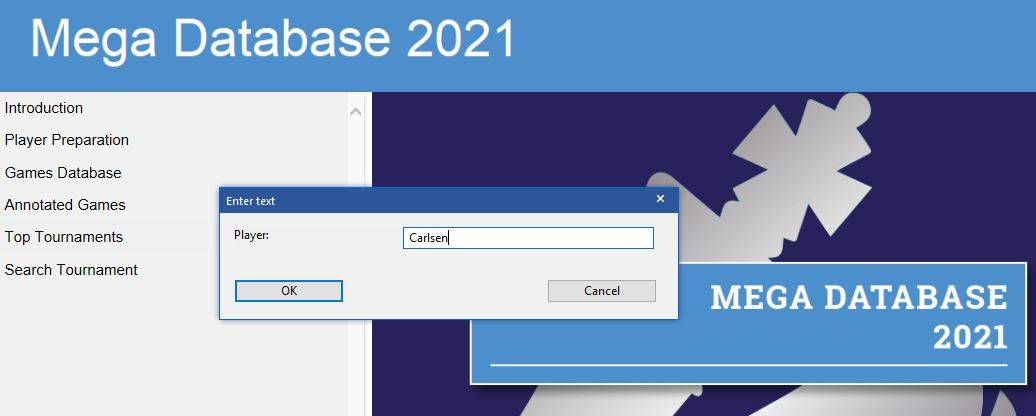
Search the database for a specific player: Just typ in the Player’s name.Who knows if you’re lucky you might even prepare against the World Champion. Find all the games in seconds.
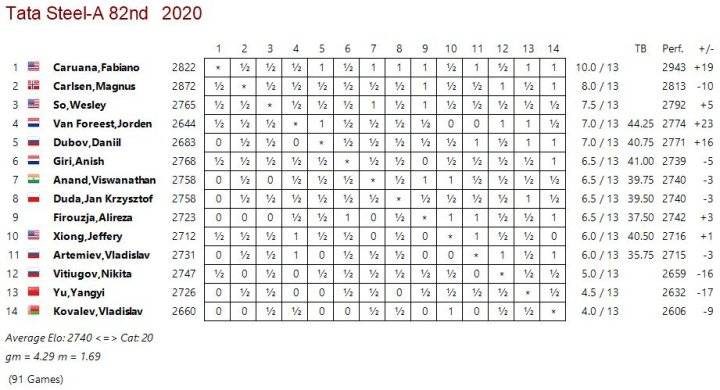
Tournament Tables to all Top-Tournaments, e.g. Tata Steel in Wijk aan Zee 2020:
The Mega Database 2021 at a glance
- Enlarged Tournament menu! Direct access to all World Championship matches and top tournaments
- More than 8,4 million games
- More than 85,000 annotated games — the world’s largest collection of games with top-class annotations
- Update service in combination with a ChessBase full version with about 250,000 new games until the end of 2021 (weekly updates with about 5,000 new games every week)
Mega Database 2021: 189.90 €
ISBN 978-3-86681-780-7
Update of Mega Database 2020: 69.90 €
Update of older Mega Databases: 119.90 €
Создание миграции репозитория
Класс модели, созданный в предыдущем разделе, определяет исходную структуру (или схему) базы данных для этого приложения. Но по мере того, как приложение продолжает расти, потребуется изменить структуру, которая, скорее всего, добавит новые сущности, но иногда также может изменять или удалять элементы. Alembic (инфраструктура миграции, используемая Flask-Migrate) сделает эти изменения схемы таким образом, чтобы не требовалось воссоздавать базу данных с нуля.
Чтобы выполнить эту, казалось бы, сложную задачу, Alembic поддерживает репозиторий миграции, который является каталогом, в котором хранится его сценарии миграции. Каждый раз, когда в схему базы данных вносится изменение, в репозиторий добавляется сценарий миграции с подробными сведениями об изменении. Чтобы применить миграции к базе данных, эти сценарии миграции выполняются в той последовательности, в которой они были созданы.
Flask-Migrate выдает свои команды через команду. Вы уже видели , который является подчиненной командой, которая является родной для Flask. Подкоманда добавляется Flask-Migrate для управления всем, что связано с миграцией базы данных. Итак, давайте создадим репозиторий миграции для microblog, запустив:
Помните, что команда полагается на переменную среды , чтобы знать, где расположено приложение Flask. Для этого приложения вы хотите установить , как описано в главе 1.
После запуска этой команды вы найдете новый каталог migrations, в котором есть несколько файлов и подкаталог версий. Все эти файлы теперь должны рассматриваться как часть вашего проекта и, их необходимо добавить в систему управления версиями.
More than 350,000 new games
Hundreds of thousands of new games played in 2019 were added to the Mega Database 2020. A lot of these games were played by renowned grandmasters and are annotated by well-known ChessBase authors.
Navigating the database is easier than ever: a new menu makes it easy to prepare for your games, to search for tournaments, to find annotated games or to access all the games in the database. One improvement: all World Championship matches and a lot of top tournaments can be directly accessed via the menu — with tables, all games, and texts about the tournaments which give you additional information and insights.
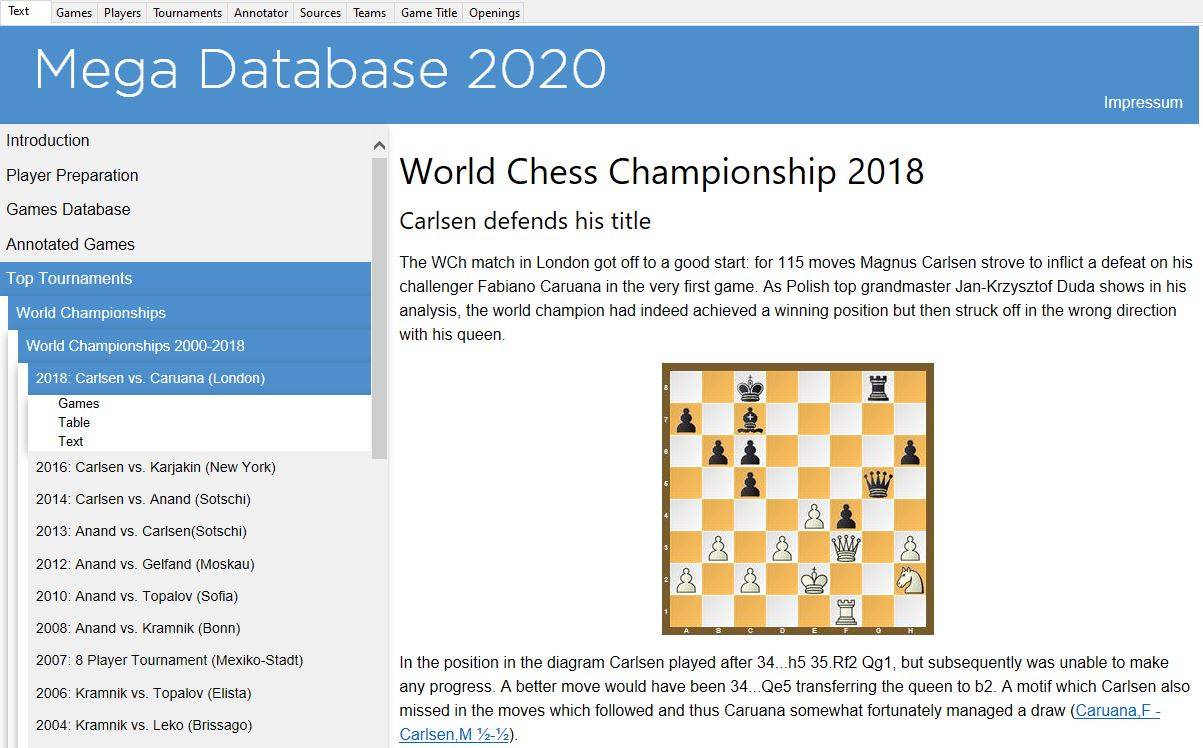
Tournament information, e.g. Tournament text to the recent World Chess Championship 2018, and No. 1 Player Magnus Carlsen vs. No. 2 in the World-rankings Fabiano Caruana. All games from the match with annotations and analysis by top grandmasters offer insights to all the games:



The ChessBase Mega Database 2020 is the premiere chess database with over eight million games from 1560 to 2019 in high quality. Packing more than 85,000 annotated games, Mega 2020 contains the world‘s largest collection of high-class analysed games. Train like a pro! Prepare for your opponents with ChessBase and the Mega Database 2020. Let grandmasters explain how to best handle your favorite variations, improve your repertoire and much more.
The ChessBase Mega Database 2020 is the premiere chess database with over eight million games from 1560 to 2019 in high quality. Packing more than 85,000 annotated games, Mega 2020 contains the world‘s largest collection of high-class analysed games. Train like a pro! Prepare for your opponents with ChessBase and the Mega Database 2020. Let grandmasters explain how to best handle your favorite variations, improve your repertoire and much more.
Preparing for your next opponent is easy: with the Mega Database it just takes seconds to find the games of your next opponent! The repertoire overview shows you which lines your opponent likes to play and statistics reveal weaknesses in his repertoire. The reference search allows you to find critical opening positions easily: put the position on the board and click the reference-button. You can filter your search, e.g. to look for annotated games to deepen your understanding.
Prepare for your next opponent or find your own games, just enter his name to get to the games:
Search the database for a specific player
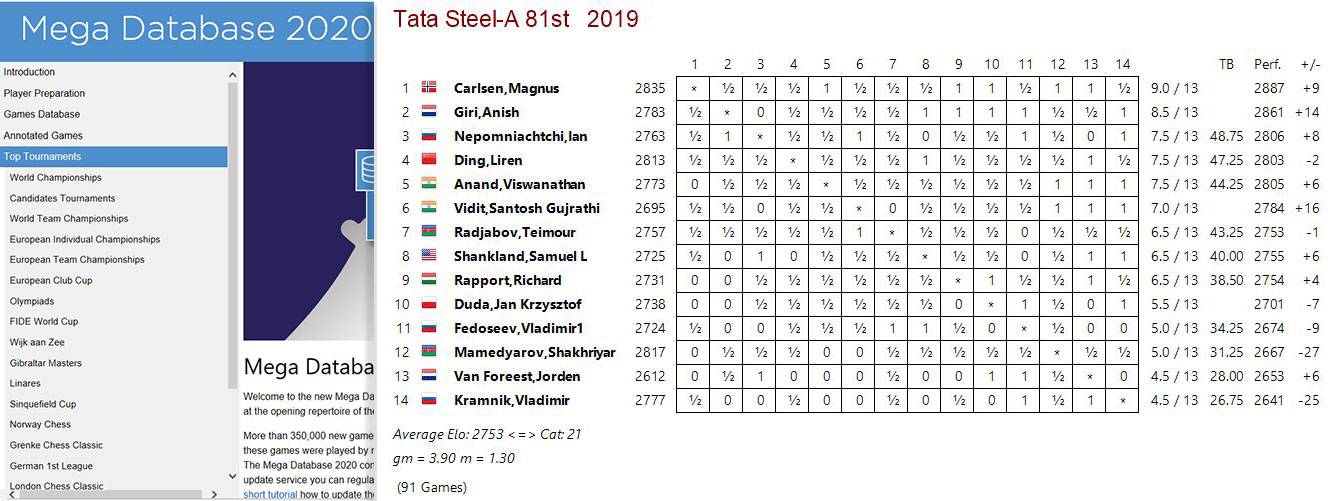
Tournament Tables to all Top-Tournaments, e.g. Tata Steel in Wijk aan Zee 2019:
Click or tap to enlarge
The Mega Database 2020 at a glance
- New design, more comfort! Direct access to all World Championship matches and selected top tournaments
- More than 8 million games
- More than 85,000 annotated games — the world’s largest collection of games with top-class annotations
- Update service with about 250,000 new games until the end of 2020 (weekly updates with about 5,000 new games every week)
We wish you a lot of joy and success with the new Mega Database 2020!
Время запуска
Я заставил вас пройти через долгий процесс создания базы данных, но я еще не показал вам, как все работает. Поскольку приложение еще не имеет логики базы данных, давайте поиграемся с базой данных в интерпретаторе Python, чтобы ознакомиться с ним. Итак, продолжайте и запустите Python. Перед запуском интерпретатора убедитесь, что ваша виртуальная среда активирована.
В командной строке Python давайте импортируем экземпляр базы данных и модели:
Начните с создания нового пользователя:
Изменения в базе данных выполняются в контексте сеанса, к которому можно получить доступ как . Множество изменений можно накапливать в сеансе, и как только все изменения были зарегистрированы, вы можете выпустить один файл , который записывает все изменения атомарно. Если в любое время во время работы над сеансом произошла ошибка, вызов отменяет сеанс и удаляет любые изменения, сохраненные в нем
Важно помнить, что изменения записываются только в базу данных при вызове. Сеансы гарантируют, что база данных никогда не останется в несогласованном состоянии
Давайте добавим другого пользователя:
База данных может ответить на запрос, возвращающий всех пользователей:
Все модели имеют атрибут запроса, который является точкой входа для запуска запросов к базе данных. Самый основной запрос — тот, который возвращает все элементы этого класса, который называется
Обратите внимание, что при добавлении этих пользователей поля автоматически устанавливались в 1 и 2
Вот еще один способ. Если вы знаете идентификатор пользователя, вы можете получить результат следующим образом:
Теперь добавим сообщение в блоге:
Мне не нужно было устанавливать значение для поля , потому что это поле имеет значение по умолчанию, которое вы можете увидеть в определении модели. А как насчет поля user_id? Напомню, что отношение , которое я создал в классе , добавляет атрибут для пользователей, а также атрибут автора для сообщений. Я назначаю автора сообщению, используя виртуальное поле автора, вместо того, чтобы иметь дело с идентификаторами пользователей. SQLAlchemy отлично подходит в этом отношении, поскольку обеспечивает абстракцию высокого уровня над отношениями и внешними ключами.
В завершении, давайте рассмотрим еще несколько запросов к базе данных:
Документация по Flask-SQLAlchemy-это лучшее место, чтобы узнать о многих вариантах, доступных для запроса к базе данных.
Для завершения этого раздела, давайте сотрем тест пользователей и сообщений, созданных выше, так что бы база данных стала чистой и готовой к следующей главе:
Скачать бесплатно в формате pgn
Второй вариант можно скачать здесь. Эта база данных также соответствует определенным критериям, важным для шахматистов разного уровня. Однако у нее есть один минус, из-за которого первый вариант становится более предпочтительным. Этот недостаток заключается в отсутствии русскоязычного интерфейса.
В любом случае возможности обеих баз будут достаточными для любого шахматиста-игрока. Они отвечают всем критериям по полноте и функциональности. Вряд ли эти базы подойдут для сложных задач. Но для начинающих игроков и любителей они будут действительно достойными и качественными продуктами.
Связи базы данных
Реляционные базы данных хороши в хранении связей между элементами данных. Рассмотрим случай, когда пользователь пишет сообщение в блоге. Пользователь будет иметь запись в таблице пользователей, и сообщение будет иметь запись в таблице сообщений. Самый эффективный способ записать кто написал данное сообщение, — связать две записи.
После того, как установлена связь между пользователем и постом, есть два типа запросов, которые нам могут понадобиться. Самый тривиальный, когда у вас есть пост и нужно знать кто из пользователей его написал. Чуть более сложный вопрос является обратным этому. Если у вас есть пользователь, то вам может понадобиться получить все написанные им записи. Flask-SQLAlchemy поможет нам с обоими типами запросов.
Расширим нашу базу для хранения постов, чтобы мы могли увидеть связи в действии. Для этого мы вернемся к нашему инструменту дизайна БД и создадим таблицу записей:
Таблица Сообщений будет иметь необходимый идентификатор, текст сообщения и метку времени. Но в дополнение к этим ожидаемым полям я добавляю поле , которое связывает сообщение с его автором. Вы видели, что у всех пользователей есть первичный ключ , который уникален. Способ связать запись блога с пользователем, который ее создал, — добавить ссылку на идентификатор пользователя, и это именно то, что является полем . Это поле называется внешним ключом (англ. foreign key). На приведенной выше схеме базы данных внешние ключи отображаются как связь между полем и полем таблицы, на которую он ссылается. Такого рода отношения называется один ко многим, потому что “один” пользователь пишет “много” Сообщений.
Измененный app/models.py показан ниже:
Новый класс будет представлять записи в блогах, написанные пользователями. Поле будет проиндексировано, что полезно, если вы хотите получить сообщения в хронологическом порядке. Я также добавил аргумент по умолчанию и передал функцию
Когда вы передаете функцию по умолчанию, SQLAlchemy установит для поля значение вызова этой функции (обратите внимание, что я не включил после , поэтому я передаю эту функцию сам, а не результат ее вызова ). В общем, это позволит работать с датами и временем UTC в серверном приложении
Это гарантирует, что вы используете единые временные метки независимо от того, где находятся пользователи. Эти временные метки будут преобразованы в локальное время пользователя, когда они будут отображаться.
Поле было инициализировано как внешний ключ для , что означает, что оно ссылается на значение из таблицы . В этой ссылке user — это имя таблицы базы данных, которую Flask-SQLAlchemy автоматически устанавливает как имя класса модели, преобразованного в нижний регистр. Класс User имеет новое поле сообщений, которое инициализируется . Это не фактическое поле базы данных, а высокоуровневое представление о взаимоотношениях между users и posts, и по этой причине оно не находится в диаграмме базы данных. Для отношения «один ко многим» поле db.relationship обычно определяется на стороне «один» и используется как удобный способ получить доступ к «многим». Так, например, если у меня есть пользователь, хранящийся в , выражение будет запускать запрос базы данных, который возвращает все записи, написанные этим пользователем. Первый аргумент указывает класс, который представляет сторону отношения «много». Аргумент определяет имя поля, которое будет добавлено к объектам класса «много», который указывает на объект «один». Это добавит выражение , которое вернет автора сообщения. Аргумент lazy определяет, как будет выполняться запрос базы данных для связи, о чем я расскажу позже. Не беспокойтесь, если эти детали не имеют для вас смысла, я покажу примеры в конце этой статьи.
Поскольку у меня есть обновления для моделей приложений, необходимо создать новую миграцию базы данных:
И миграция должна быть применена к базе данных:
Если проект хранится в системе управления версиями, не забудьте добавить в него новый сценарий миграции.
How to activate the automatic update service
The Online Mega-Update 2018 delivers about 5,000 current games every week, a total of about 250,000! This will keep your Mega 2018 up to date from January to December 2018. With ChessBase 14 you can easily set up the update.
All you need is your Mega 2018 serial number
If you purchased the Mega Database 2018 in DVD form, you will find the activation code for the update service in the box below the DVD.
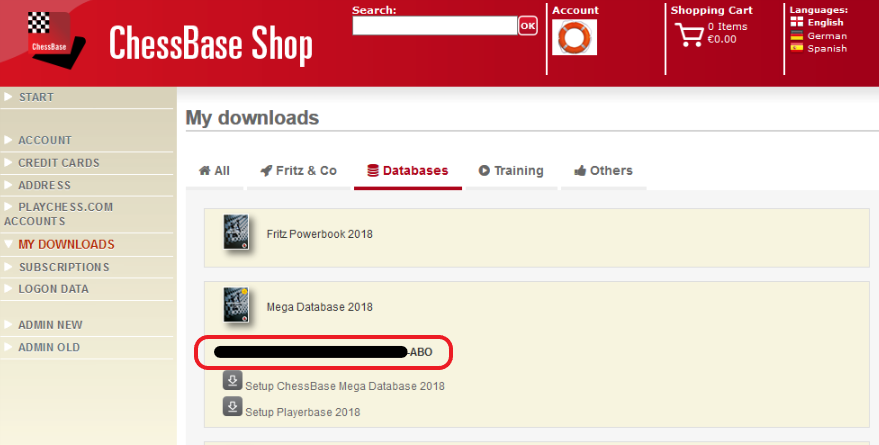
If you have purchased the database as a download in our shop, you will find the serial number in your shop account under “My Downloads” in the subcategory “Databases” (marked red in the picture below):
Click or tap to expand
Now open your ChessBase 14 program. Is your Mega 2018 installed as a “reference database”? Please right-click on the Mega2018 in the ChessBase database window, select Properties → “Reference”.
At the lower left corner of the main window you will find the button “New Games” net to the Mega Update icon:
Download new games
The window “Data Abo Manager” opens in CB 14:
In ChessBase 14, the Mega Subscription will be linked directly to your ChessBase account. Pro tip: Through this connection, you can access all games from any of your computers, even during a trip from your notebook, without having to activate the updates on each device individually.
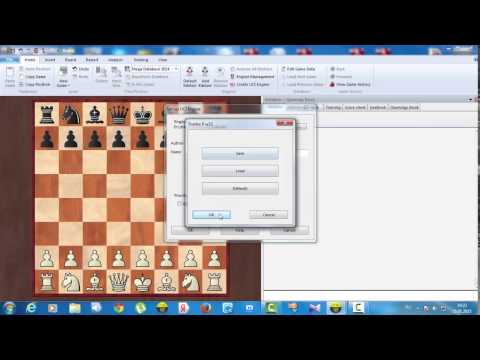


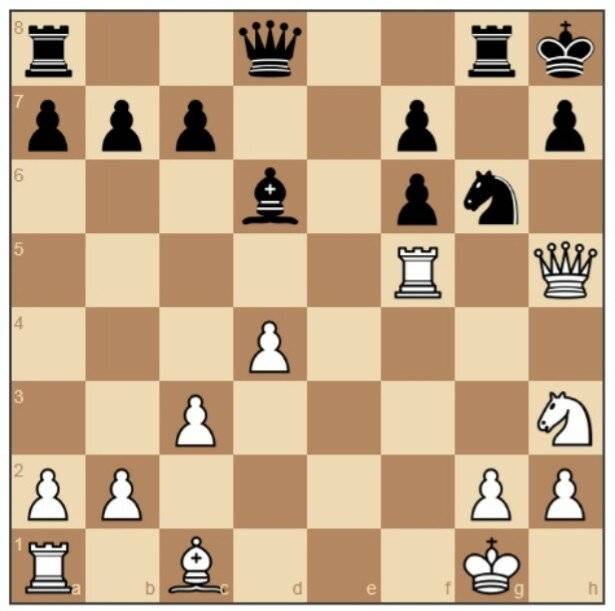

Press “Login” and log in with your ChessBase account and password. If you do not have an account yet, create a free account:
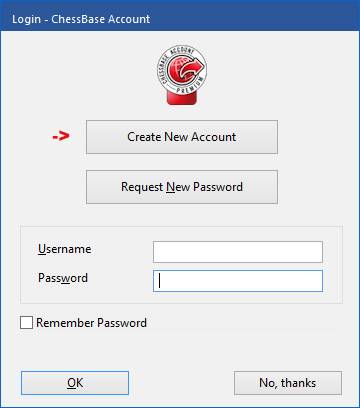
Create new ChessBase Account
Now click on “Update MegaBase 2018” in ChessBase 14 and on the “Activate subscription” button at the top.
The following dialogue box opens:
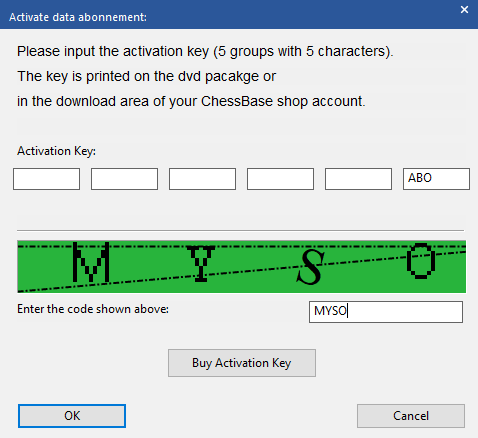
In this dialogue box, enter your Mega 2018 activation key. Underneath, enter the four green letters in the small box
After successful activation, start the update of your Mega 2018 via the button “Download games”.
Manage your active subscriptions
DONE! Now the Mega Database 2018 will automatically update itself. This is the fastest and easiest way to keep your database up to date!
Transferring old subscriptions
If you already own the databases Mega 2014, Mega 2015, Mega 2016 or Mega 2017, then you can easily integrate them into your ChessBase account. Simply use the function “transfer subscriptions”.
Previous subscriptions can easily be integrated into your ChessBase account at the push of a button
The following dialogue opens:
Transferring old databases to your current ChessBase account
As soon as you have linked the updates to your ChessBase account in this way, you can access all games from any of your computers, including the notebook, without having to activate the updates on each device individually. All activated subscriptions will appear in the list, from Mega Database 2009 to Mega 2018.
One more thing
If you have the Mega Database 2018 installed and keep it up to date, you do not need to update the versions of the Mega Database from previous years. Each new mega automatically includes the newly entered or corrected historical chess games. The weekly game updates of the current Mega2018 include the latest games.
The perfect combination
If you install ChessBase 14 together with the Powerbook 2018 and the Mega Database 2018 on your notebook, you have the same combination as the World Champion!

Order now: ChessBase 14 + Mega Database 2018!
Модели баз данных
Данные, которые будут храниться в базе данных, будут представлены набором классов, обычно называемых моделями баз данных. Уровень ORM в SQLAlchemy будет выполнять переводы, необходимые для сопоставления объектов, созданных из этих классов, в строки в соответствующих таблицах базы данных.
Поле обычно используется во всех моделях и используется как первичный ключ. Каждому пользователю в базе данных будет присвоено уникальное значение идентификатора, сохраненное в этом поле. Первичные ключи в большинстве случаев автоматически назначаются базой данных, поэтому мне просто нужно указать поле , помеченное как первичный ключ.
Итак, теперь, когда я знаю, что мне нужно для таблицы моих пользователей, я могу перевести это в код в новом модуле app/models.py:
Созданный выше класс наследует от , базового класса для всех моделей из Flask-SQLAlchemy. Этот класс определяет несколько полей как переменные класса
Поля создаются как экземпляры класса , который принимает тип поля в качестве аргумента, плюс другие необязательные аргументы, которые, например, позволяют мне указать, какие поля уникальны и индексированы, что важно для эффективного поиска базы данных ,
Метод сообщает Python, как печатать объекты этого класса, что будет полезно для отладки. Вы можете увидеть метод в действии в сеансе интерпретатора Python ниже:
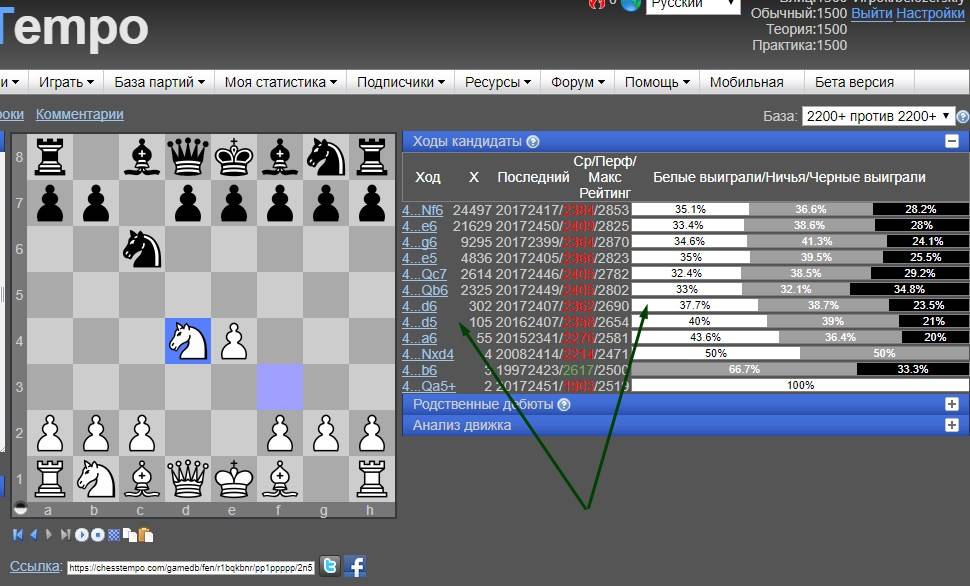
Зачем нужны шахматные базы?
Примечательно, что в двадцатом веке шахматные базы существовали в формате сборников, книг и газетных вырезок. Дальше произошло формирование «Шахматного информатора». Вследствие этого, можно сделать вывод, что потребность в знаниях и сведениях о том, как играют другие шахматисты, была всегда.
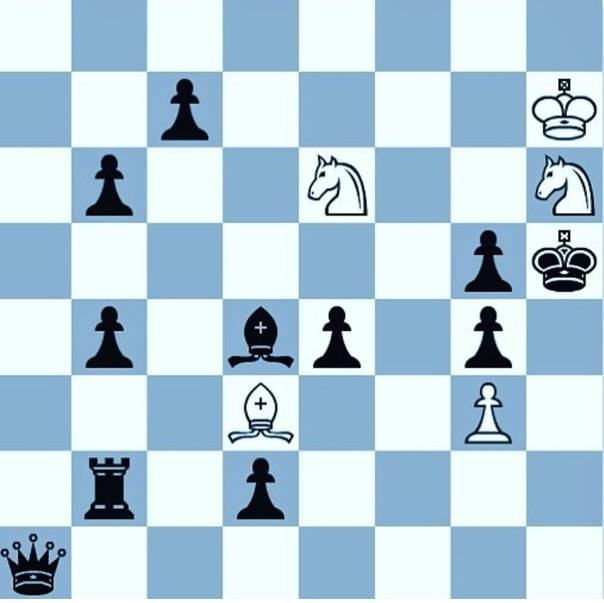


Именно это позволяет любому человеку совершенствовать свои навыки, следить за тенденциями, учиться на партиях лучших игроков. Многие люди видели, как шахматисты применяют ходы, варианты или стратегии, подсмотренные у других игроков. Притом они могут обладать не самым высоким уровнем умений.
Можно ли считать такой подход плагиатом? Конечно, нет. В шахматах авторские права не запрещают повторять ходы, вариации и стратегии. Все знания и навыки здесь приобретены столетиями за счет опыта других игроков. Главным фактором тут выступает умение работать с информацией. Базы партий – это массив, позволяющий накапливать и извлекать информацию. Это полезно для подготовки, обучения и самодисциплины.
Создание новой базы данных
Новая база данных будет создана сразу после того, как вы поместите в нее первую партию.
Шаг 1. Загружаем файл PGN ( например, с игрового сайта) и открываем его при помощи программы ChessBase (желательно, чтобы ChessBase была назначена программой по умолчанию для открытия файлов PGN).
Файл PGN открыт в программе ChessBase
Шаг 2. Делаем двойной щелчок по название файла (на рисунке выше выделен красной рамкой). После этого партия откроется в новом окне. Слева будет доска, справа нотации (по умолчанию).
Шахматная партия открыта в новом окне
Шаг 3. Теперь можно приступать к созданию базы данных и сохранению в ней открытой партии. Имеет смысл хранить базы данных не на системном диске «С», а на диске, предназначенном для хранения данных, например диске «D». На диске «D» можно создать общую папку для хранения баз данных, а внутри её, отдельные папки для каждого дебюта (Итальянская партия, Испанская партия и т.д.).
Для большей надежности, базы данных можно хранить на локальном диске «D», создав под каждый дебют отдельную папку
Далее заходим в меню Файл — Сохранить как, указываем папку, в которой хотим сохранить партию, прописываем название базы данных (лучше назвать базу данных так, как называется дебют, в данном случае «Защита Каро-Канн) и нажимаем кнопку Создать/Открыть.
Указываем имя файла (это будет имя базы данных) и нажимаем кнопку Создать/Открыть
Шаг 4. При необходимости вносим изменения в описание партии и щелкаем ОК.
После того, как база данных создана, она появится в списке стартового окна ChessBase.
Созданная база данных «Защита Каро-Канн», появилась в списке стартового окна
Обратите внимание, что в папке «Защита Каро-Канн» появился не только файл с расширением CBH, но множество других файлов, которые нужны для нормальной работы базы данных. Кроме файла cbh, в папке появились и другие файлы: ini, cit, cib, cbtt, cbt, cbs, cbp, cbm, cbg, cbe, cbc, cba
Кроме файла cbh, в папке появились и другие файлы: ini, cit, cib, cbtt, cbt, cbs, cbp, cbm, cbg, cbe, cbc, cba
Благодаря тому, что под каждую базу данных создана отдельная папка, путаницы с файлами будет меньше.
Процесс обновления базы данных и откатка изменений Upgrade и Downgrade
На данный момент приложение находится в зачаточном состоянии, но это не помешает обсудить, что будет в стратегии миграции базы данных в будущем. Представьте, что у вас есть приложение на вашей машине разработки, а также есть копия, развернутая на производственный сервер, который находится в сети и используется.
Предположим, что для следующей версии вашего приложения вам нужно внести изменения в свои модели, например, нужно добавить новую таблицу. Без миграции вам нужно будет выяснить, как изменить схему вашей базы данных, как на локальном хосте, так и на вашем сервере, и это может быть большой проблемой.
Но с поддержкой миграции базы данных, после изменения моделей в приложении вы создаете новый сценарий миграции ( flask db migrate ), вы, вероятно, просмотрите его, чтобы убедиться, что автоматическое создание сделало правильные вещи, а затем примените изменения в базе данных разработки ( flask db upgrade ). Вы добавите сценарий миграции в систему управления версиями и зафиксируете его.
Когда вы будете готовы выпустить новую версию приложения на свой production сервер, все, что вам нужно сделать, это захватить обновленную версию приложения, которая будет включать в себя новый сценарий миграции и запустить . Alembic обнаружит, что база данных не обновлена до последней редакции, и выполнит все новые сценарии миграции, созданные после предыдущего выпуска.
Как я упоминал ранее, у вас также есть команда , которая отменяет последнюю миграции. Хотя вам вряд ли понадобится этот вариант в момент рабочей эксплуатации, Вы можете найти его очень полезным во время разработки. Возможно, вы сгенерировали сценарий миграции и применили его, только чтобы обнаружить, что внесенные изменения не совсем то, что вам нужно. В этом случае можно понизить рейтинг базы данных, удалить сценарий миграции, а затем создать новый, чтобы заменить его.
Базы шахматных партий в онлайне
Все базы шахматных партий в онлайне – разные, имеют много отличий
Перед их использованием обязательно нужно обратить внимание на определенные критерии. Например, к ним относятся:
- полнота – какую пользу вы можете получить от базы, если в ней присутствует только 100 партий? Найти то, что необходимо, можно, но тут многое зависит от везения. В хорошей базе количество партий должно приближаться к отметке в 2 000 000;
- актуальность – то есть, необходимо обладать базами партий за 2020, 2019, 2018 годы и дальше, без пробелов. Но в некоторых базах, к сожалению, могут отсутствовать данные за какие-то года;
- функциональность – база обязательно должна характеризоваться понятной и удобной навигацией. Тут должны быть сортировка и фильтры (по игрокам, рейтингам, годам, дебютам). Если этого нет в базе, то она будет бесполезной. Искать вручную данные придется очень долго и сложно.
В соответствии с целями и уровнем пользователей, может присутствовать разный метод применения баз. Отличаются цели у тренеров, шахматистов-любителей, действующих гроссмейстеров.
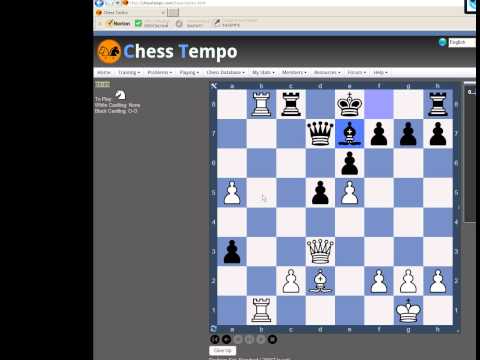
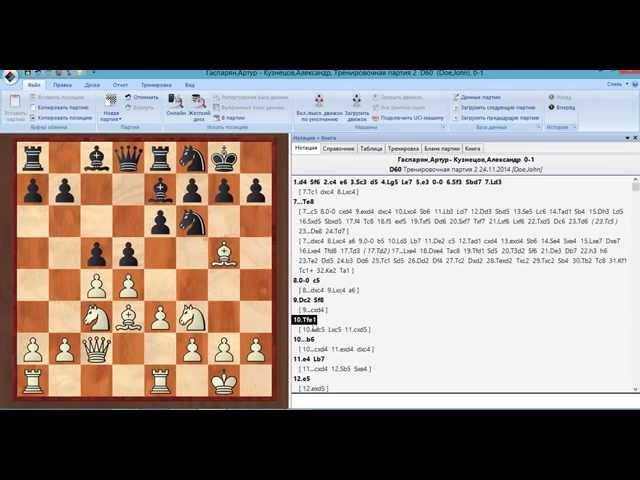
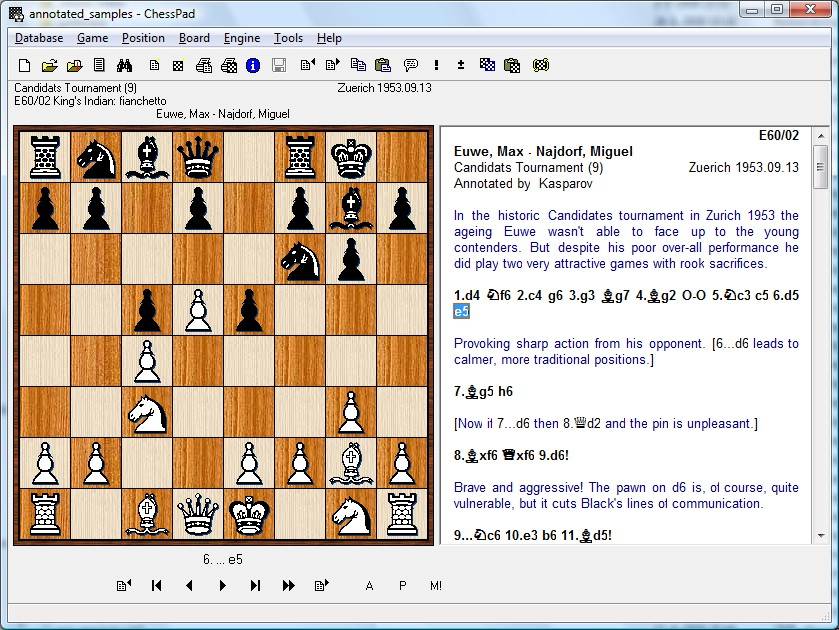
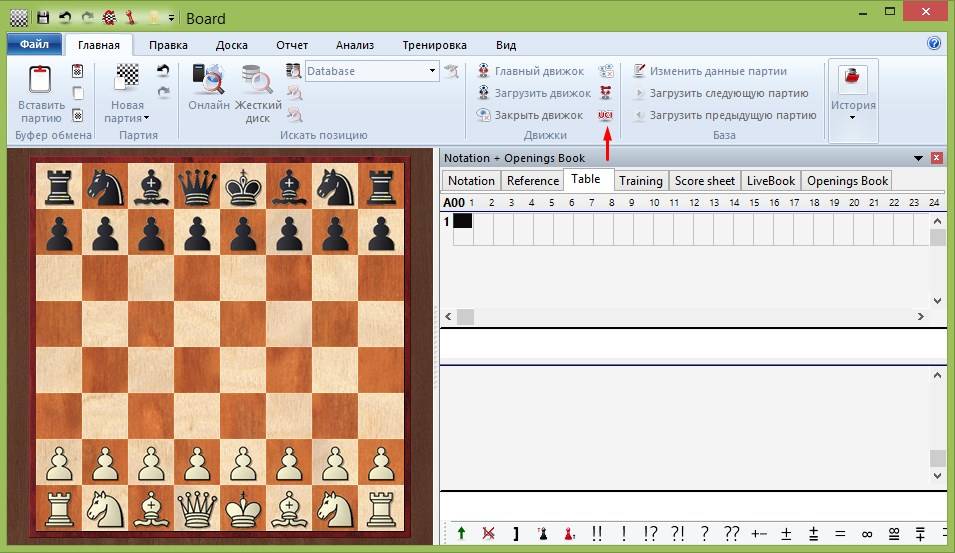


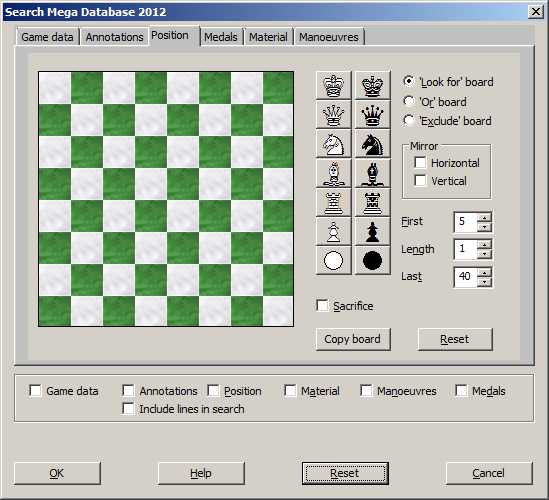

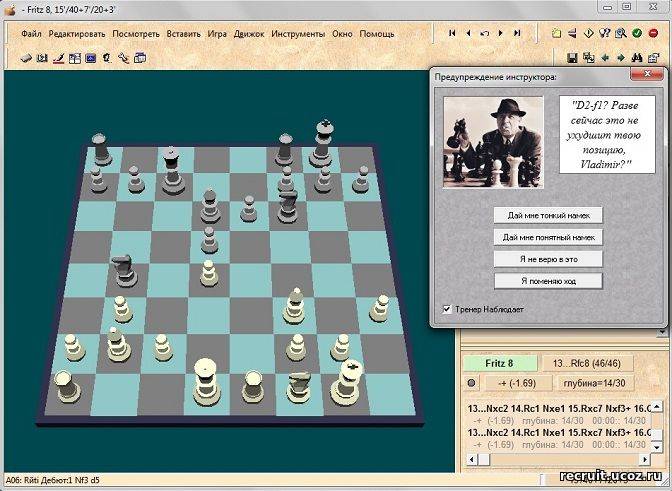
Например, сильным мастерам, гроссмейстерам рекомендуется подключать базы данных к своей программе по шахматам (иногда платной), использовать ее можно для решения разных задач. Шахматисты с уровнем пониже обычно используют не такие продвинутые методы. Здесь можно обойтись даже онлайн-версиями шахматных баз.
Причинами приобретения баз обычно становятся необходимость обучения и приобретения новых навыков в игре. Кстати, шахматист сразу может соревноваться и практиковаться в новых знаниях и умениях, применяя их на деле – например, играть с компьютером на нашем сайте.
Конфигурация Flask-SQLAlchemy
Во время разработки я собираюсь использовать базу данных SQLite. Базы данных SQLite являются наиболее удобным выбором для разработки небольших приложений, иногда даже не очень маленьких, так как каждая база данных хранится в одном файле на диске и нет необходимости запускать сервер баз данных, как MySQL и PostgreSQL.
У нас есть два новых элемента конфигурации для добавления в файл конфигурации:
Расширение Flask-SQLAlchemy принимает местоположение базы данных приложения из переменной конфигурации . Как вы помните из главы 3, в целом рекомендуется установить конфигурацию из переменных среды и предоставить резервное значение, когда среда не определяет переменную. В этом случае я беру URL-адрес базы данных из переменной среды , и если это не определено, я настраиваю базу данных с именем app.db, расположенную в основном каталоге приложения, которая хранится в переменной .
Параметр конфигурации установлен в значение False, чтобы отключить функцию Flask-SQLAlchemy, которая мне не нужна, которая должна сигнализировать приложению каждый раз, когда в базе данных должно быть внесено изменение.
База данных будет представлена в приложении, как database instance. Механизм миграции базы данных также будет иметь экземпляр. Это объекты, которые необходимо создать после приложения, в файле :
Я внес три изменения в скрипт init. Во-первых, я добавил объект , который представляет базу данных. Затем я добавил еще один объект, который представляет механизм миграции. Надеюсь, вы увидите образец работы с расширениями Flask. Большинство расширений инициализируются как эти два. Наконец, я импортирую новый модуль под названием внизу. Этот модуль определит структуру базы данных.
shell context или лекарство от геморроя
Помните, что вы делали в начале предыдущего раздела, сразу после запуска интерпретатора Python? Первое, что вы сделали, это запустили некоторые операции импорта:
В то время как вы работаете над своим приложением, вам нужно будет очень часто тестировать функционал в оболочке Python, поэтому повторять вышеуказанный импорт каждый раз будет утомительно. Команда — еще один очень полезный инструмент в командной оболочке команд. — это второе “ядро”, реализующее , после запуска. Цель этой команды-запустить интерпретатор Python в контексте приложения. Что это значит? Рассмотрим следующий пример:
При регулярном сеансе интерпретатора имя неизвестно, если явно не импортировано, но при использовании команда предварительно импортирует экземпляр приложения. Прикол заключается не в том, что предварительно импортирует приложение, а в том, что вы можете настроить «shell context», который представляет собой список других имен для предварительного импорта.
Следующая функция в microblog.py создает контекст оболочки, который добавляет экземпляр и модели базы данных в сеанс оболочки:
Декоратор регистрирует функцию как функцию контекста оболочки. Когда запускается команда , она будет вызывать эту функцию и регистрировать элементы, возвращаемые ею в сеансе оболочки. Причина, по которой функция возвращает словарь, а не список, заключается в том, что для каждого элемента вы также должны указывать имя, под которым оно будет ссылаться в оболочке, которое задается индексами словаря.
После того, как вы добавите функцию обработчика , вы можете работать с объектами базы данных, не импортируя их:
Выводы
Оттачивая свое шахматное мастерство, много времени приходится уделять анализу сыгранных партий. Благодаря программе ChessBase, можно хранить все сыгранные партии «под рукой». Чтобы не возникло путаницы, желательно создавать не одну базу данных, а несколько, чтобы была возможность классифицировать шахматные партии.
При создании баз данных, следует сохранять в них не только собственные партии, но и партии сильнейших шахматистов мира. В этом случае, удобно будет сравнивать свои партии с партиями профессионалов.
Из статьи становится понятно, что создание собственных шахматных баз данных при помощи ChessBase, не требует больших усилий. Потраченное время будет окуплено с лихвой.