Environment
- Python 3.6.3
- tensorflow-gpu: 1.3.0
- Keras: 2.0.8
New results (after a great number of modifications due to @Akababa)
Using supervised learning on about 10k games, I trained a model (7 residual blocks of 256 filters) to a guesstimate of 1200 elo with 1200 sims/move. One of the strengths of MCTS is it scales quite well with computing power.
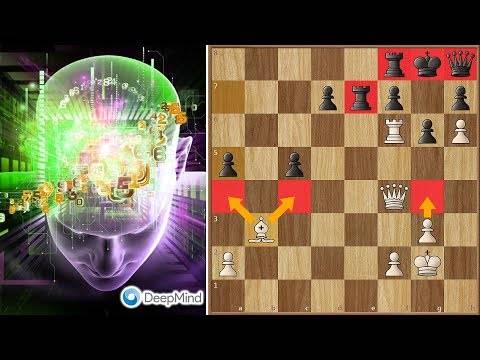
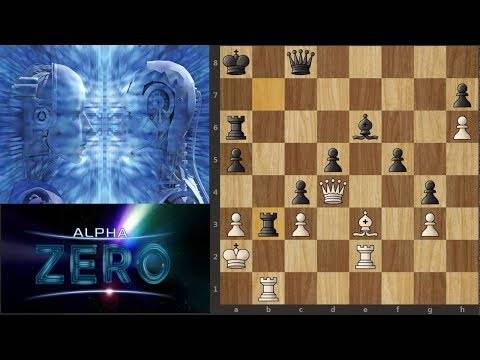
Here you can see an example where I (black) played against the model in the repo (white):

Here you can see an example of a game where I (white, ~2000 elo) played against the model in this repo (black):

First “good” results
Using the new supervised learning step I created, I’ve been able to train a model to the point that seems to be learning the openings of chess. Also it seems the model starts to avoid losing naively pieces.
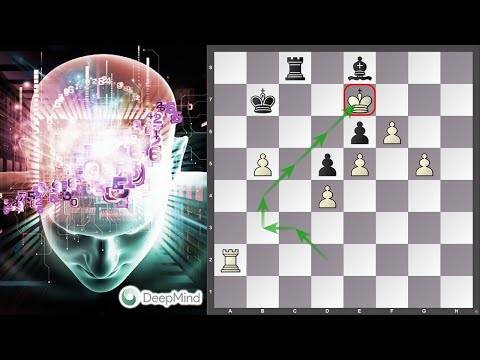
Here you can see an example of a game played for me against this model (AI plays black):

Here we have a game trained by @bame55 (AI plays white):

This model plays in this way after only 5 epoch iterations of the ‘opt’ worker, the ‘eval’ worker changed 4 times the best model (4 of 5). At this moment the loss of the ‘opt’ worker is 5.1 (and still seems to be converging very well).





Modules
Supervised Learning
I’ve done a supervised learning new pipeline step (to use those human games files “PGN” we can find in internet as play-data generator).
This SL step was also used in the first and original version of AlphaGo and maybe chess is a some complex game that we have to pre-train first the policy model before starting the self-play process (i.e., maybe chess is too much complicated for a self training alone).
To use the new SL process is as simple as running in the beginning instead of the worker “self” the new worker “sl”.
Once the model converges enough with SL play-data we just stop the worker “sl” and start the worker “self” so the model will start improving now due to self-play data.
python src/chess_zero/run.py sl
To avoid overfitting, I recommend using data sets of at least 3000 games and running at most 3-4 epochs.
Reinforcement Learning
This AlphaGo Zero implementation consists of three workers: , and .
- is Self-Play to generate training data by self-play using BestModel.
- is Trainer to train model, and generate next-generation models.
- is Evaluator to evaluate whether the next-generation model is better than BestModel. If better, replace BestModel.
Distributed Training
Now it’s possible to train the model in a distributed way. The only thing needed is to use the new parameter:
–type distributed: use mini config for testing, (see src/chess_zero/configs/distributed.py)
So, in order to contribute to the distributed team you just need to run the three workers locally like this:
python src/chess_zero/run.py self --type distributed (or python src/chess_zero/run.py sl --type distributed) python src/chess_zero/run.py opt --type distributed python src/chess_zero/run.py eval --type distributed
GUI
uci launches the Universal Chess Interface, for use in a GUI.
To set up ChessZero with a GUI, point it to (or rename to .sh).
For example, this is screenshot of the random model using Arena’s self-play feature:
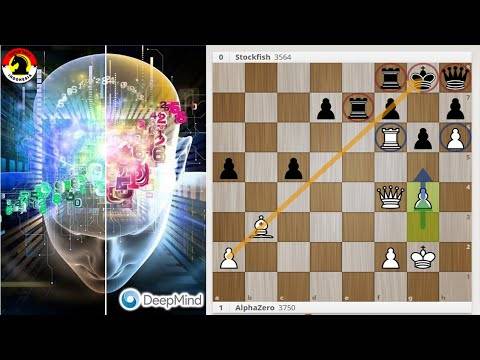
AlphaZero против Stockfish
К новости о разгромной победе никому неизвестной Альфа Зеро над великим и ужасным Стокфиш в шахматном мире отнеслись, как к революции. Но есть несколько следующих «но».









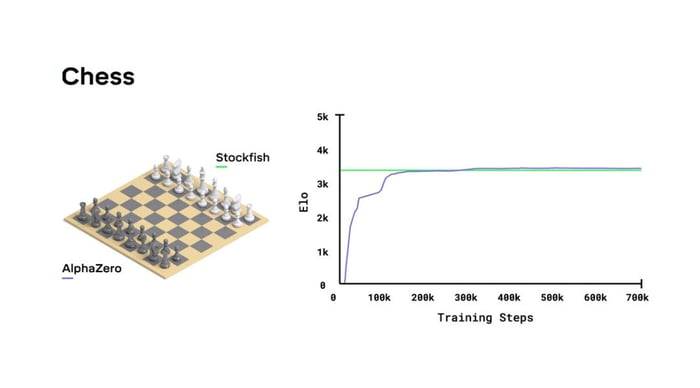
Из представленного DeepMind доклада «Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm» того же 5 декабря 2017 года и графика обучения в нем, видно, что разница в силе АльфаЗеро и Стокфиш совсем не велика, как могло показаться по итогу матча.
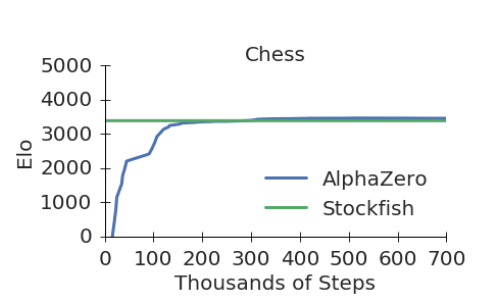
Программы играли на совершенно разном оборудовании. Стокфиш получил обычный CPU, пусть и 64-ядерный, а АльфаЗеро – 4 TPU (Tensor Processing Unit, тензорный процессор). А для обучения АльфаЗеро вообще было применено 5000 TPU первого поколения и 64 TPU второго поколения. Процессоры имеют разную архитектуру и сравнить их напрямую тяжело. Если оценить производительность по количеству операций с плавающей запятой в секунду, то система из 4-х TPU окажется на 2 порядка более мощной чем 64 ядра CPU. Задействовать Стокфиш на сравнимой мощности невозможно, таких CPU процессоров нет, а для архитектуры TPU Стокфиш не предназначен. Таким образом, сравнить программы на равных мощностях не получится.

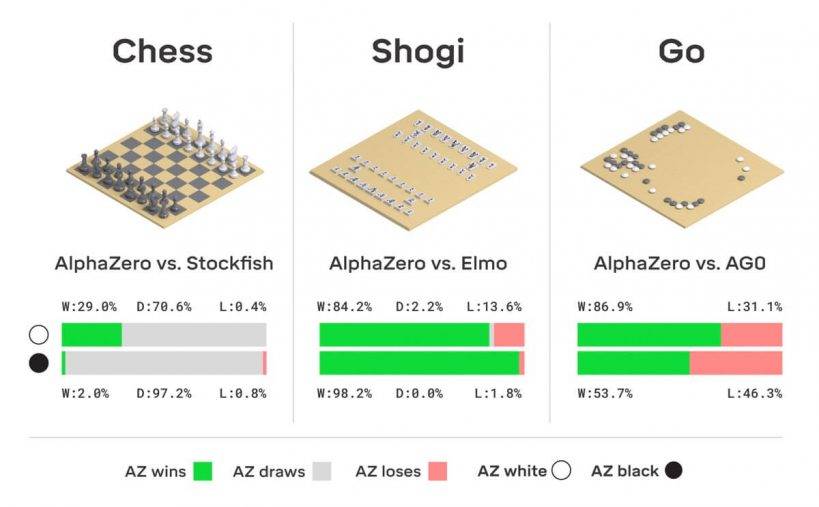
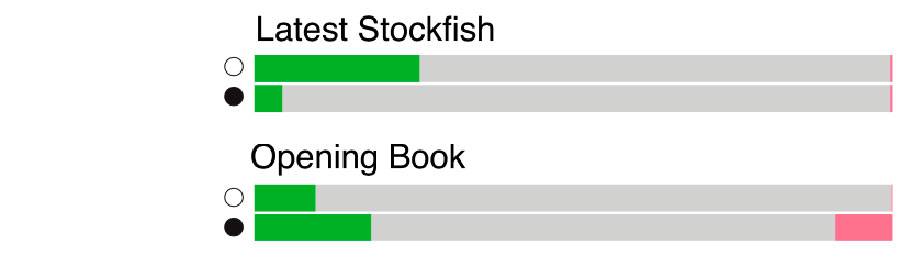
Помимо этого, Стокфиш был лишен дебютной библиотеки, на которую ориентирован, а также играл с нетипичным контролем времени – 1 минута на ход. В довесок, противником АльфаЗеро был Стокфиш прошлогодней 8-й версии.
Особенности Alpha Zero
Alpha Zero – это не традиционный шахматный движок. Это программа, которой не нужны ни дебютные, ни эндшпильные базы данных. Ей не были прописаны сложные алгоритмы вычисления оценки, как это было сделано для Komodo, для того же Stockfish и других движков. За считанные часы AlphaZero сыграла сама с собой многое множество партий и уяснила для себя, что и как.
История применения нейронных сетей и машинного обучения для шахматных движков на самом деле не нова. В 2015 году с помощью подхода, называемого «обучение с подкреплением» Мэтью Лай разработал Giraffe, шахматную программу уровня международного мастера. Оценочная функция Giraffe была полностью основана на нейронной сети, в отличие от классических шахматных программ, в которых функция оценки представляет собой набор критериев из фиксированных правил, хорошо известных шахматистам.

Позднее Мэтью Лай был приглашен в DeepMind. Он прекратил работу над Giraffe, но применил свои наработки для AlphaZero, которая тоже использует нейронные сети для оценочной функции. Но не только для этого. Переборный механизм в Giraffe был основан на классическом «поиске с основным вариантом», наследнике «alpha-beta-отсечения», разработанного еще в 1962 году. Однако AlphaZero для перебора применяет «метод Монте-Карло поиска по дереву», который тоже управляется нейронной сетью. Это принципиальное отличие AlphaZero от Giraffe и конечно от шахматных движков старой школы.
Note
I’m the creator of this repo. I (and some others collaborators did our best: https://github.com/Zeta36/chess-alpha-zero/graphs/contributors) but we found the self-play is too much costed for an only machine. Supervised learning worked fine but we never try the self-play by itself.









Anyway I want to mention we have moved to a new repo where lot of people is working in a distributed version of AZ for chess (MCTS in C++): https://github.com/glinscott/leela-chess
Project is almost done and everybody will be able to participate just by executing a pre-compiled windows (or Linux) application. A really great job and effort has been done is this project and I’m pretty sure we’ll be able to simulate the DeepMind results in not too long time of distributed cooperation.
So, I ask everybody that wish to see a UCI engine running a neural network to beat Stockfish go into that repo and help with his machine power.
Установить Leela Chess Zero
Порядок установки под Windows
- Скачивается и распаковывается необходимая последняя версия движка
- В папку с распакованным движком помещается выбранная сеть
- Драйвера видеокарты обновляются на свежие
- Программа подключается к оболочке, как любой другой UCI-движок
Примечания:
- Для оболочки Fritz может понадобиться патч, улучшающий загрузку нестандартных машин; для Fritz 15 – это патч 15.36
- Помимо lcexe в архиве с движком имеется приложение client.exe; с его помощью пользователь может принять участие в обучении нейросетей LCZero – для игры и анализа с движком на ПК не требуется
Начальная установка, как правило, проходит гладко, однако, судя по комментариям в среде пользователей, с дальнейшей работой и настройкой могут возникать трудности.
О превосходстве Alpha Zero
Говоря о скорости перебора, которую использовали программы, то данные конечно впечатляют: Альфа Зеро с помощью дерева поиска Монте-Карло просматривал 80 тысяч позиций в секунду, тогда как Стокфиш – 70 миллионов. Опять же здесь есть свои нюансы, если приводить скорость перебора в качестве аргумента силы. Однако нельзя не сказать о том, что Alpha Zero гораздо избирательнее и применяемый ею подход в какой-то степени ее «очеловечивает».
Кроме того, переход от перебора, управляемого множеством правил, которые могут содержать в себе изъяны, связанные с предубеждениями или субъективностью шахматных экспертов, к переходу, управляемому нейронной сетью, это бесспорно благо, которое быть может в будущем расскажет много нового о шахматах.
Подводя итог, учитывая, что разница в силе игры не такая большая и зная, что Alpha Zero имела оборудование значительно более мощное, нежели Стокфиш, однозначно сказать о превосходстве, не оставляющем сомнений, сложно
Но это на самом деле маловажно, потому что Альфа Зеро это не еще один шахматный движок. Это прикладной пример использования искусственного интеллекта против традиционного программного алгоритма и определенно большой и качественный шаг в области изучения и совершенствования интеллектуальных машин
Скачать Leela Chess Zero
LCZero – не типичный UCI-движок, но все же он поддерживает универсальный шахматный интерфейс и потому может быть использован на ПК в шахматной оболочке, такой как, например, Chessbase, Fritz или Arena. Однако установка Лилы и ее настройка для эффективной и удобной работы потребует от пользователя несколько больших сил и знаний, а может быть и вложений, нежели в случае того же Стокфиша, Комодо или Гудини.







Скачать Leela Chess Zero можно с официального сайта разработчика lczero.org. Программа является бесплатной. Скачать потребуется: 1) файл движка lcexe и 2) файл сети
1) Непосредственно сам движок распространяется в трех версиях: Blas, OpenCL и Cuda.
- Blas потребляет в своей работе только ресурсы CPU (центрального процессора) и в отличие от OpenCL- и Cuda-версий не обращается к видеокарте, поэтому весьма значительно уступает им в силе и скорости
- OpenCL задействует GPU (графический процессор) с поддержкой OpenCL2
- Cuda использует возможности относительно свежих GPU NVIDIA и работает только с ними
Чтобы узнать о поддержке видеокарты стандарта OpenCL 1.2, можно воспользоваться программой GPU-Z (распространяется бесплатно). Платы AMD поддерживают OpenCL 1.2 последние полдесятка лет (на архитектуре GCN). Интегрированная в CPU графика (применяется, как правило, на ноутбуках) также подойдет при условии поддержки вышеупомянутого стандарта. Встроенные графические процессоры AMD позволят использовать OpenCL-версию LCZero, начиная с семейства Kaveri.
Cuda превосходит OpenCL, но поддерживает только видеокарты NVIDIA, начиная с GTX 600-й серии, т.е. с семейства Kepler (как правило не старше 2013 года) или новее (Maxwell, Pascal, Turing). С каждым новым релизом движка его требования могут расти – чем мощнее видеокарта, тем эффективнее она себя проявит.
2) В своей работе Leela Chess Zero использует тренируемые разработчиками и пользователями нейросети.
Для скачивания доступно множества сетей и применить из них можно любую, но стоит обратить внимание, что последняя сеть не всегда является самой сильной